Most Business Data Is Messy. Limelight Fixes It Automatically
How Limelight's data cleaning engine identifies and normalizes real-world data inconsistencies automatically.

1. Executive Summary & Key Implications for Leaders
Business data is often a silent killer of AI ROI. While datasets may appear structured at first glance, hidden inconsistencies—such as mixed formats, shorthand values, and duplicated entities—degrade analytics and lead to AI hallucinations. This blog explores how Limelight's automated cleaning engine transforms raw, messy data into reliable assets, saving engineering teams weeks of manual labor and ensuring trustworthy model outputs.
Key ROI Implications for Leaders:
- Reclaim Engineering Time: Eliminate the need for custom regex scripts and manual CSV wrangling, allowing your team to focus on building product features rather than cleaning data.
- Ensure AI Trustworthiness: Prevent immeasurable costs associated with AI hallucinating on flawed data in client-facing applications.
- Accelerate Time-to-Value: Transition from raw data ingestion to machine-ready datasets in seconds, not weeks.
- Scale Without Bottlenecks: Process hundreds of thousands of rows instantly, ensuring that data quality never becomes a bottleneck for your analytics pipelines.
Most Business Data Is Messy. Limelight Fixes It Automatically
Most business datasets appear structured at first glance. Columns exist, rows are populated, and values look reasonable. However, once the data is inspected more closely, inconsistencies quickly emerge. Mixed formats, shorthand values, duplicated entities, malformed identifiers, and missing values are extremely common.
These issues silently degrade analytics pipelines and AI systems. Even a small number of inconsistencies can lead to broken SQL queries, incorrect aggregations, or misleading model outputs. Every hour your engineering team spends writing custom regex scripts or manually wrangling CSVs is an hour they aren't building a product and when bad data slips through, the cost of an AI hallucinating on a client-facing application is immeasurable.
To understand how frequently these problems occur and how Limelight eliminates them we uploaded a sample invoice dataset into Limelight's data cleaning engine and analyzed how the system detects and normalizes real-world inconsistencies. The results show how even a seemingly clean CSV file can contain dozens of hidden data problems.
Experimental Setup & Performance at Scale
To evaluate the system, we used a typical business dataset containing invoice records. The dataset included standard columns like transaction_id, client_name, invoice_amount, billing_date, status, and region.
At a glance, the dataset appears structured and usable. Each row represents a transaction and each column represents a specific attribute of the invoice. However, Limelight isn't just built for small samples; the engine is designed to process hundreds of thousands of rows in seconds, ensuring your data pipelines never bottleneck. Once this dataset was processed by the Limelight engine, the system identified numerous structural inconsistencies.
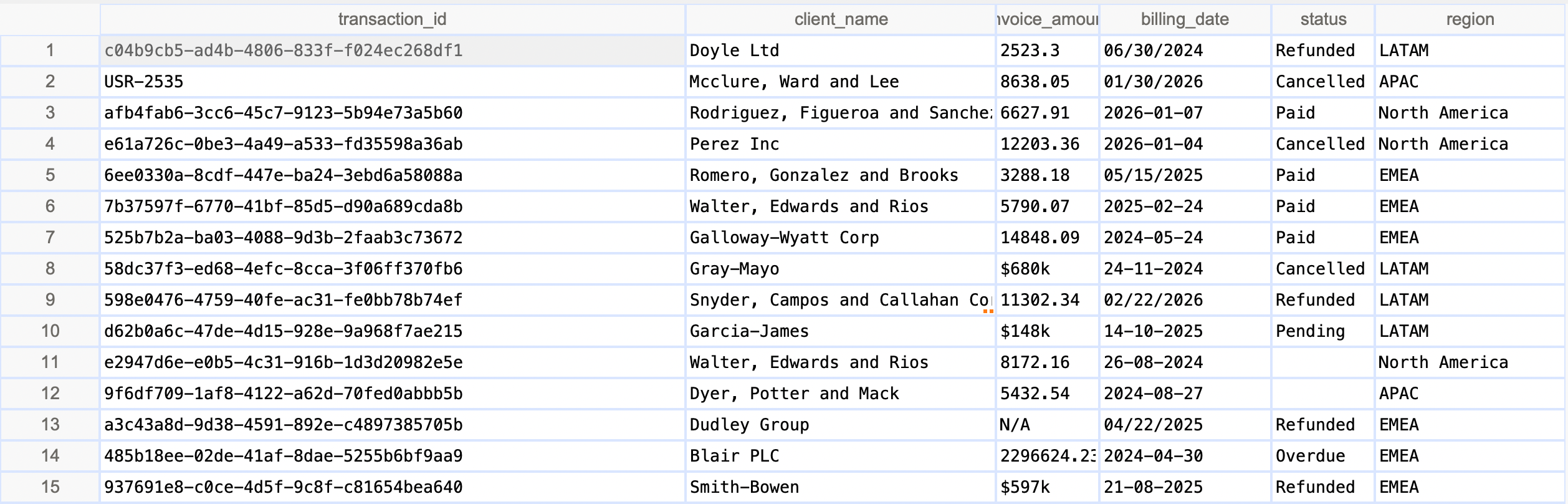
The sample dataset contains typical business columns like transaction IDs, dates, and amounts.
Automatic Issue Detection
After ingesting the CSV file, the system performs an initial profiling stage across every column. This stage analyzes value distributions, dominant formatting patterns, and statistical anomalies.
In this example dataset, the engine detected 92 potential data issues:
- 52 duplicate entities
- 10 ID format mismatches
- 12 normalization failures
- 6 null values
- 12 outlier values
Instead of silently modifying the dataset—a massive risk for any enterprise—the system highlights the exact cells responsible for these issues, allowing users to inspect the underlying data inconsistencies.

Limelight Dashboard highlighting the 92 flagged errors in the grid view.
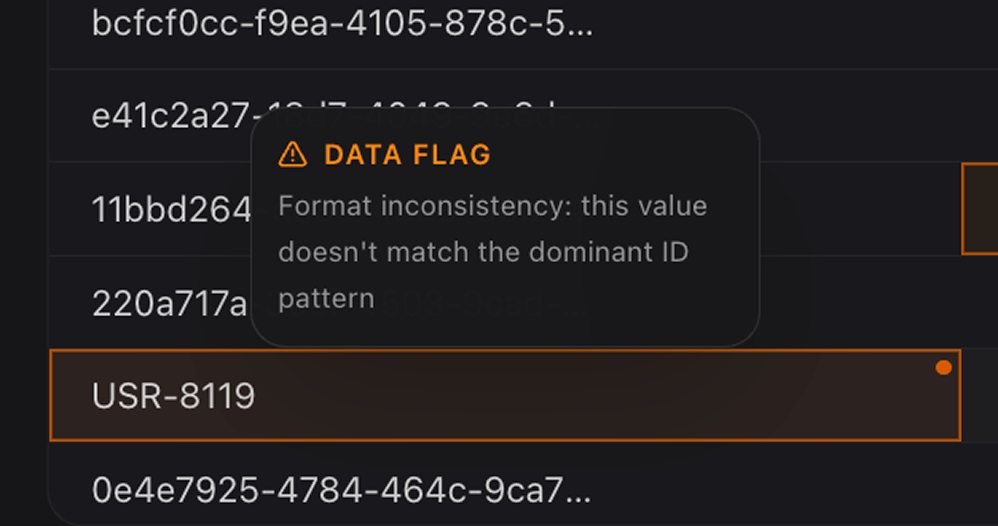
Specific cells are flagged with clear icons to indicate formatting or logic errors.
How Limelight Normalizes Data for AI and Analytics
- Identifier Pattern Analysis: Structured datasets typically rely on consistent identifiers. In this dataset,
transaction_idpredominantly followed a UUID pattern, but the engine flagged outliers likeUSR-8119that break the dominant pattern. Downstream, this prevents join failures. - Currency Normalization: The
invoice_amountcolumn contained standard numeric values (like8376.68) mixed with shorthand notation (like318k). The data cleaning engine detects these shorthand representations and normalizes them into machine-readable numeric values (e.g.,318000), making the column instantly ready for SQL aggregation. - Advanced Base Currency Handling: For global datasets containing multiple currencies, Limelight provides a "Base Currency" feature. Users can set a target base currency and provide specific conversion rates. The engine then automatically converts all values into the standardized base currency, ensuring financial accuracy across international records.
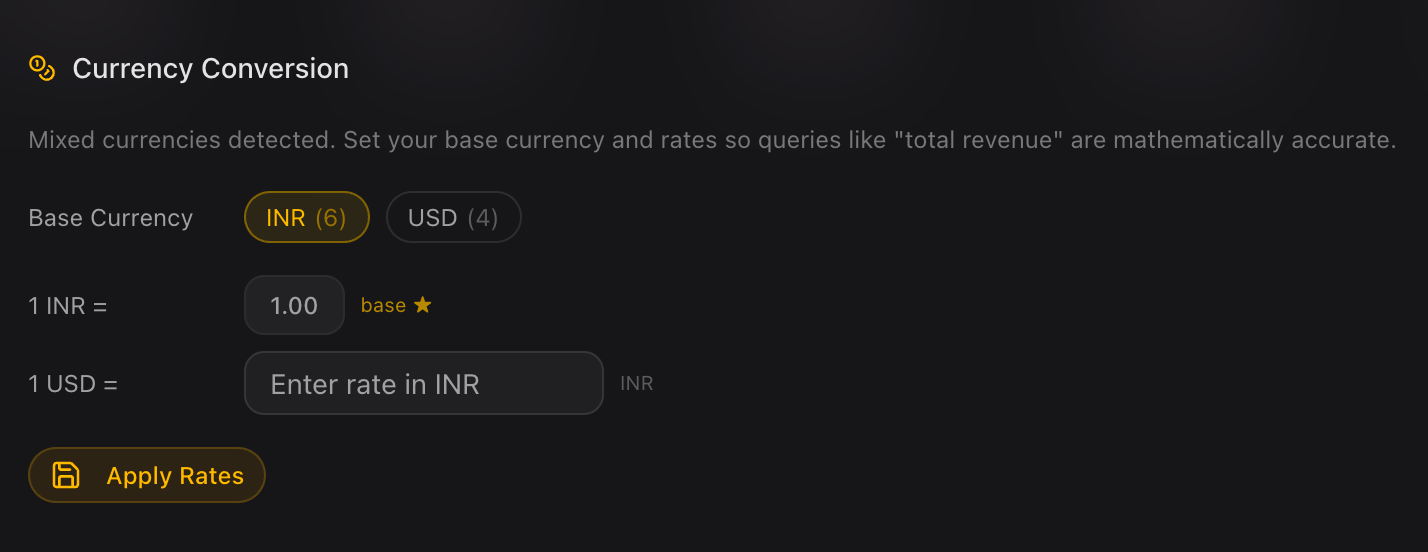
Set base currencies and conversion rates to unify global financial data instantly.
- Date Format Inconsistencies: The
billing_datecolumn contained several formats including06/30/2024and2026-01-07. Mixing formats breaks time-based queries. Limelight standardizes these values into a single ISO format (e.g.,2024-06-30), ensuring consistent interpretation across databases and machine learning pipelines.
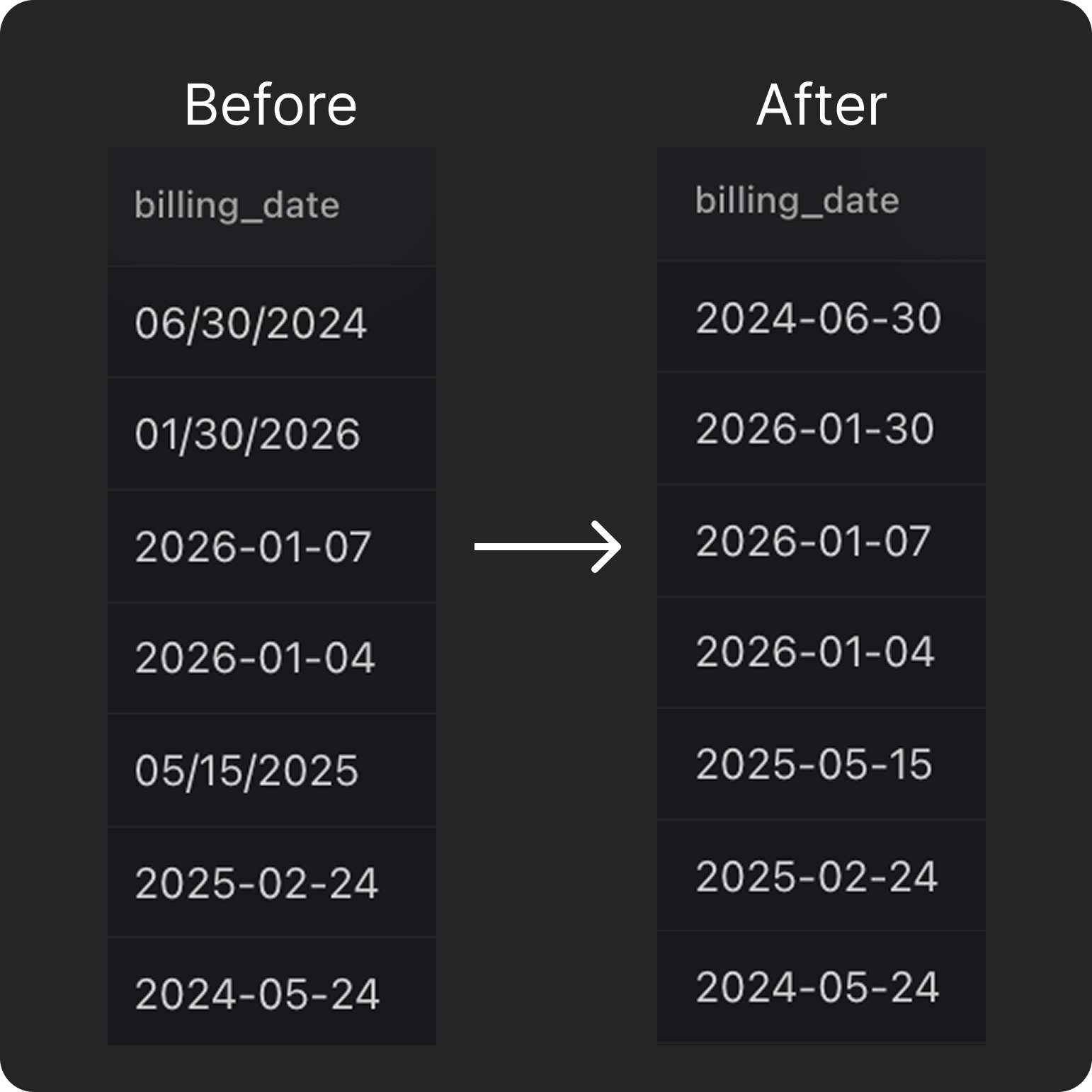
Limelight automatically detects and fixes inconsistent date formats across the entire column.
- Manual Overrides & Instant Export: Automation is powerful, but control is essential. Limelight allows users to manually edit values directly within the interface to handle unique edge cases. Once the data is refined to perfection, you can instantly download the cleaned, machine-ready CSV, ready for your downstream production systems.
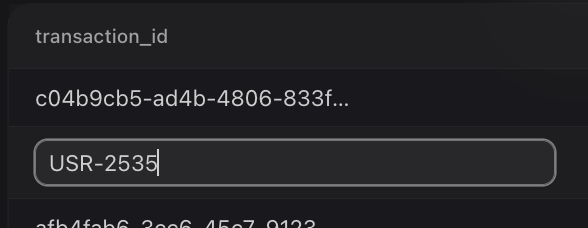
Edit values directly in the grid for total control before exporting your cleaned data.
- Duplicate Entity Detection: The engine flagged repeated values like "Baker and Sons" to help users determine whether duplicates represent expected data or underlying data quality issues.

The system identifies potential duplicates, allowing for quick deduplication without manual effort.
Side-by-Side: Messy vs. Clean Data
The real power of Limelight is visible when looking at the original data alongside the engine's suggested cleaning actions.
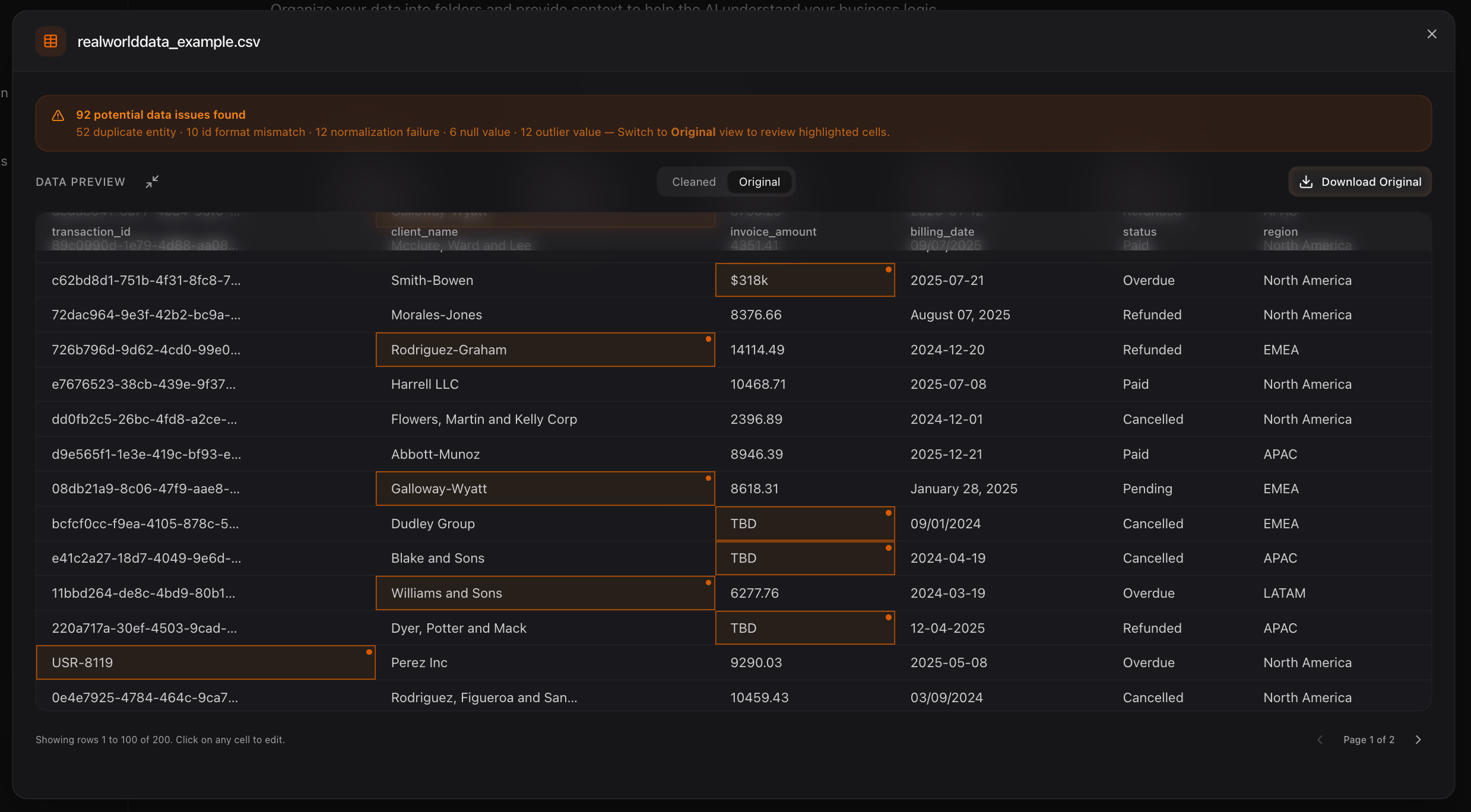
Original Messy Data: Columns contain mixed formats, ID mismatches, and shorthand values that break downstream systems.
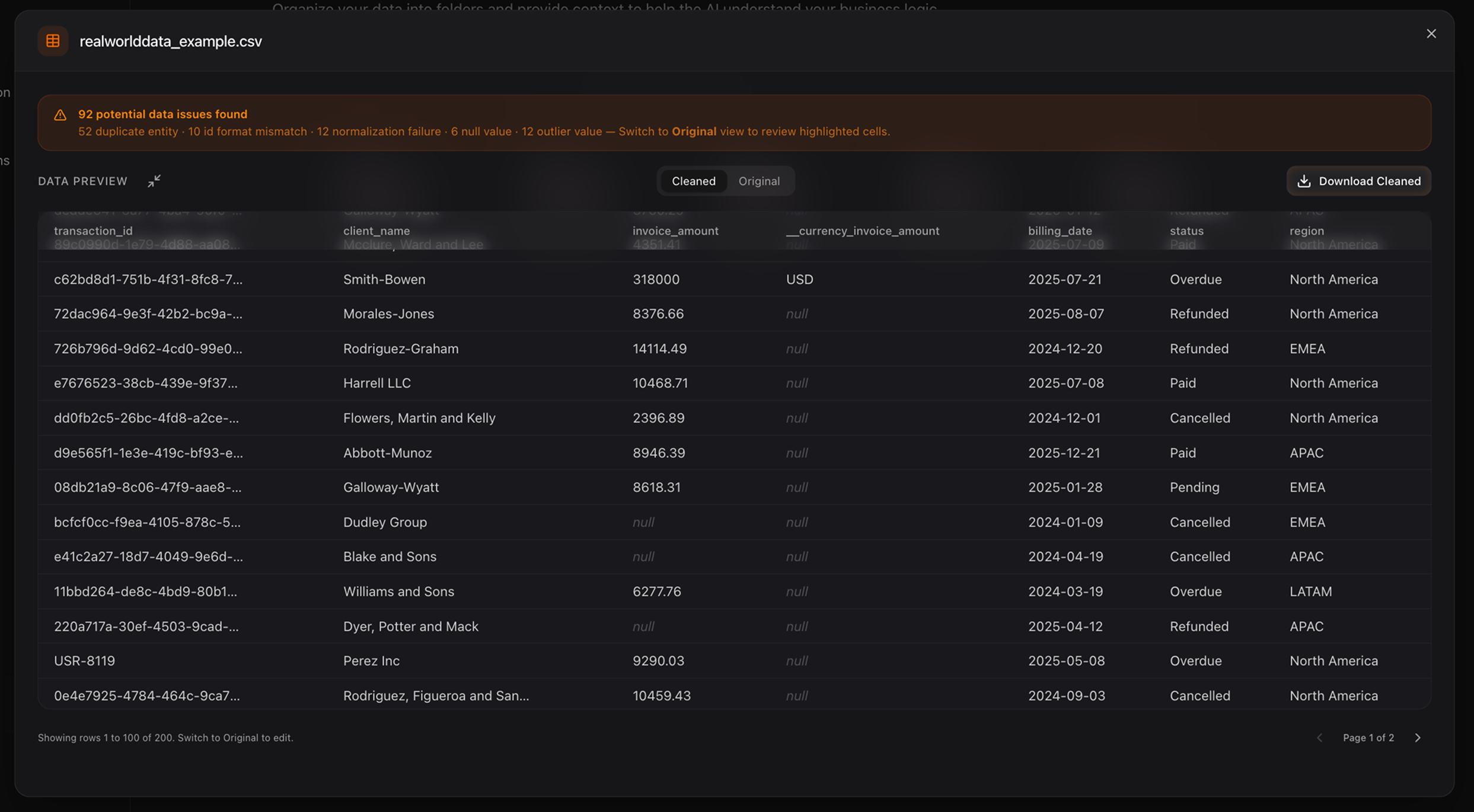
Limelight's Normalized Output: Every value is machine-readable, identifiers are standardized, and outliers are flagged for review.
The ROI of an Automated Cleaning Pipeline
Behind the interface, the cleaning engine operates through a multi-stage pipeline: schema profiling, pattern inference, and normalization procedures. Finally, detected issues are categorized and surfaced in the interface so users can inspect and validate the system's findings.
Rather than altering the original data irreversibly, the engine preserves both the original and cleaned versions so users can audit changes when necessary. By automatically identifying and standardizing structural inconsistencies at ingestion time, Limelight ensures that analytics pipelines operate on reliable, machine-readable datasets.
For a business, this means eliminating the weeks of manual data engineering required to prep data for AI. It transforms raw, messy knowledge into a structured asset instantly.
Conclusion
This experiment demonstrates that even small structured datasets can contain dozens of hidden inconsistencies. Reliable analytics and trustworthy AI systems ultimately depend on one fundamental requirement: clean data. Automating this process is a critical step toward building dependable data infrastructure.
Stop letting bad data break your AI and analytics pipelines. See how much time Limelight can save your engineering team.